
Using Claude Code to Modernize My Courses
How a semester’s worth of student feedback became a set of tracked GitHub issues — and then a fleet of Claude Code agents that did the work.

Every course accumulates cruft. Slides drift a year (or five) out of date. The “permitted materials” rule for the exam gets announced slightly differently every term.
Assignment rubrics live in my head instead of on the page. End-of-term feedback gets read once, nodded at, and forgotten. None of this is hard to fix. It’s just tedious, and tedium is exactly what gets deferred until “next year.”
This year I tried something different. I sat down with Claude Code and a single organizing idea: turn every intention into a tracked GitHub issue, then point agents at the issue. The issue becomes the spec; the agents become the labor. Here’s what that looked like across my security course — and how I then cloned the whole approach into two other courses (ML systems and censorship) without redoing the thinking.
Start With The Feedback, End With An Issue
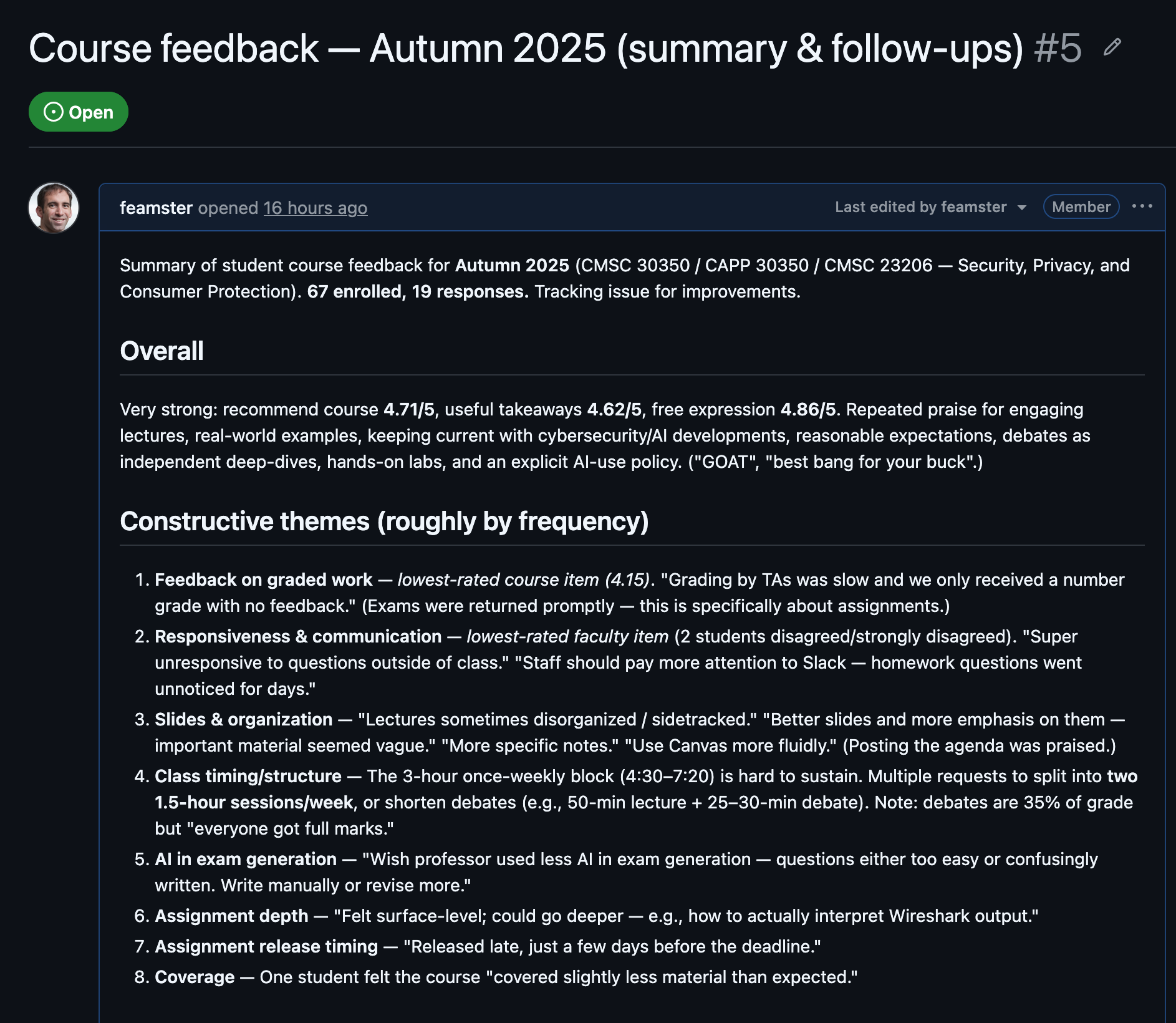
I exported the course evaluations as a PDF and dropped it in my Downloads folder. Step one was simply: read this and tell me what students actually said. Claude summarized it — the praise, but more usefully the constructive themes: feedback on graded work was slow and opaque, the once-a-week three-hour block was a slog, exam questions were uneven, some assignments felt surface-level, and a few materials were hard to find.
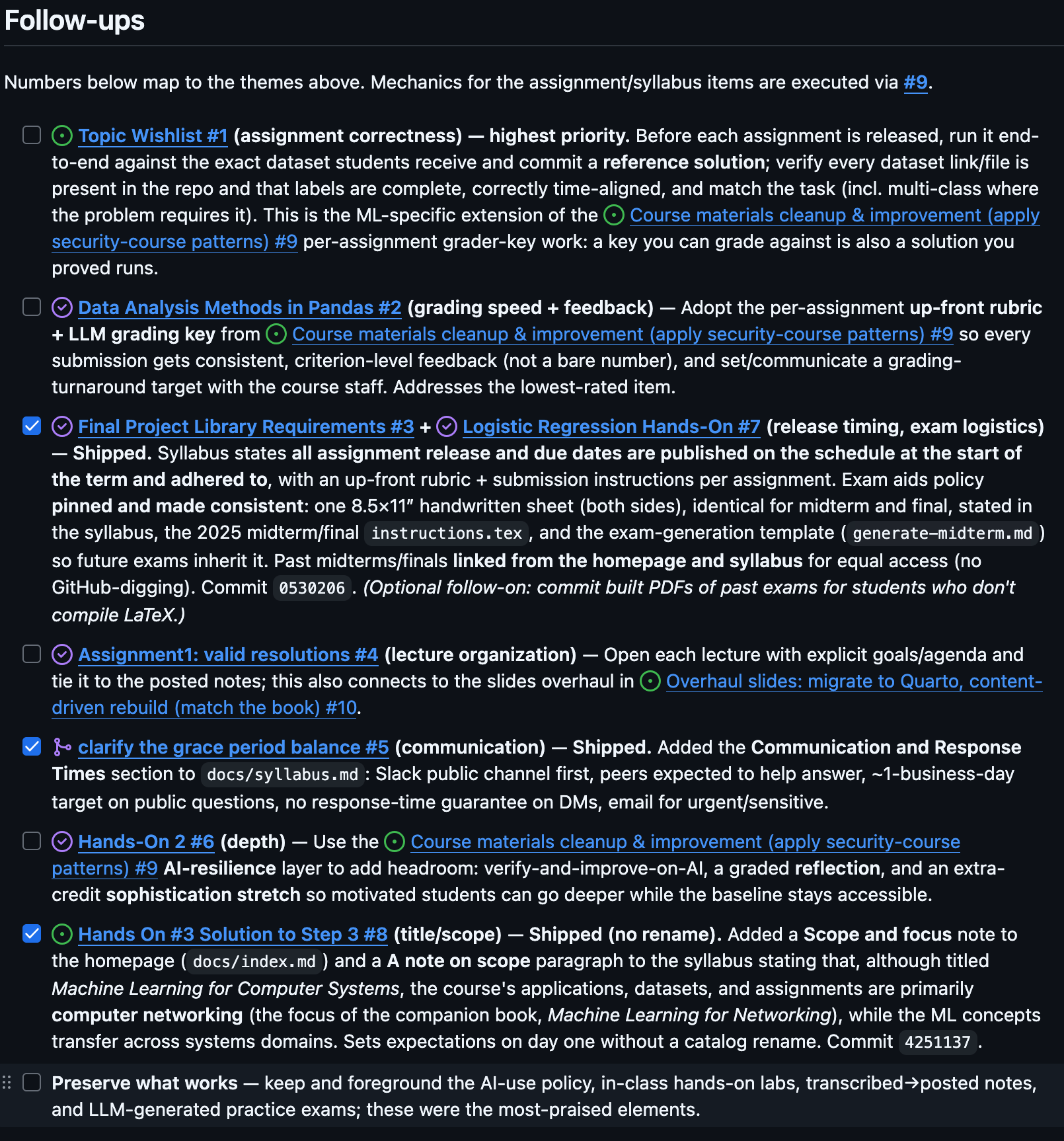
Then the important move: file it as a tracking issue with a checklist, one box per theme. The security course’s Course feedback — Autumn 2025 (summary & follow-ups) issue is the canonical worked example: a feedback summary up top, then a checklist where each box — rubrics, the syllabus communication/response-times section, the debate rubric, the exam-logistics standardization — gets checked off as the corresponding change ships. That issue became the backbone for everything that followed. Instead of a vague memory of “students wanted better feedback,” I had a durable, checkable artifact — and every change I shipped later got a one-line “shipped in commit X” note against its box. The issue is both the to-do list and the changelog.
Assignments: Rubrics, Auto-Grading, And “AI-Resilience”
The loudest signal was about graded work, so we restructured the assignments (tracked as one of the checklist boxes in issue #5). Each one became a self-contained folder with an up-front rubric the students see, plus a separate grading key designed so I can grade with an LLM consistently. That second part forced a useful discipline: if a model is going to grade a submission, the assignment has to ask for evidence in the text (paste the actual packet fields, the token JSON, the metrics) rather than artifacts a grader can’t open.
The part I’m most pleased with is what I started calling AI-resilience. Students will use AI — that’s fine, and I tell them so. The trick is to design tasks where doing the thinking yourself, with AI as a tool, still beats a one-shot prompt:
Build on personal artifacts (your own capture, your own account).
Verify and correct the model against your own data.
Write a short reflection on what surprised you.
Be ready to defend it live.
The rubric rewards exactly that.
Syllabus And Exams: Killing Inconsistency
A lot of “policy” problems are really consistency problems. So we added a Communication & Response Times section to the syllabus (public channel first, peers expected to help, a stated turnaround), pinned that assignment release and due dates are published on day one, and wrote an actual debate rubric so a third of the grade isn’t a vibe.
Exams were the cleanest example of the consistency fix (another box on issue #5). The “permitted materials” rule — one double-sided handwritten sheet, no devices — now appears byte-for-byte identical in the syllabus, on the course homepage, in the LaTeX exam instructions, in the exam style file, and in the exam-generation templates, so future exams inherit it automatically and it can never get announced differently at exam time. We also built and published the past-exam PDFs students kept asking for. Along the way an agent discovered that one past final’s source files were empty — a latent bug that would have bitten me at the worst possible moment — and reconstructed it.

Slides: The Big Fan-Out
The headline project was the slides: roughly two dozen PowerPoint decks, years of accretion, some 70–150 slides each.
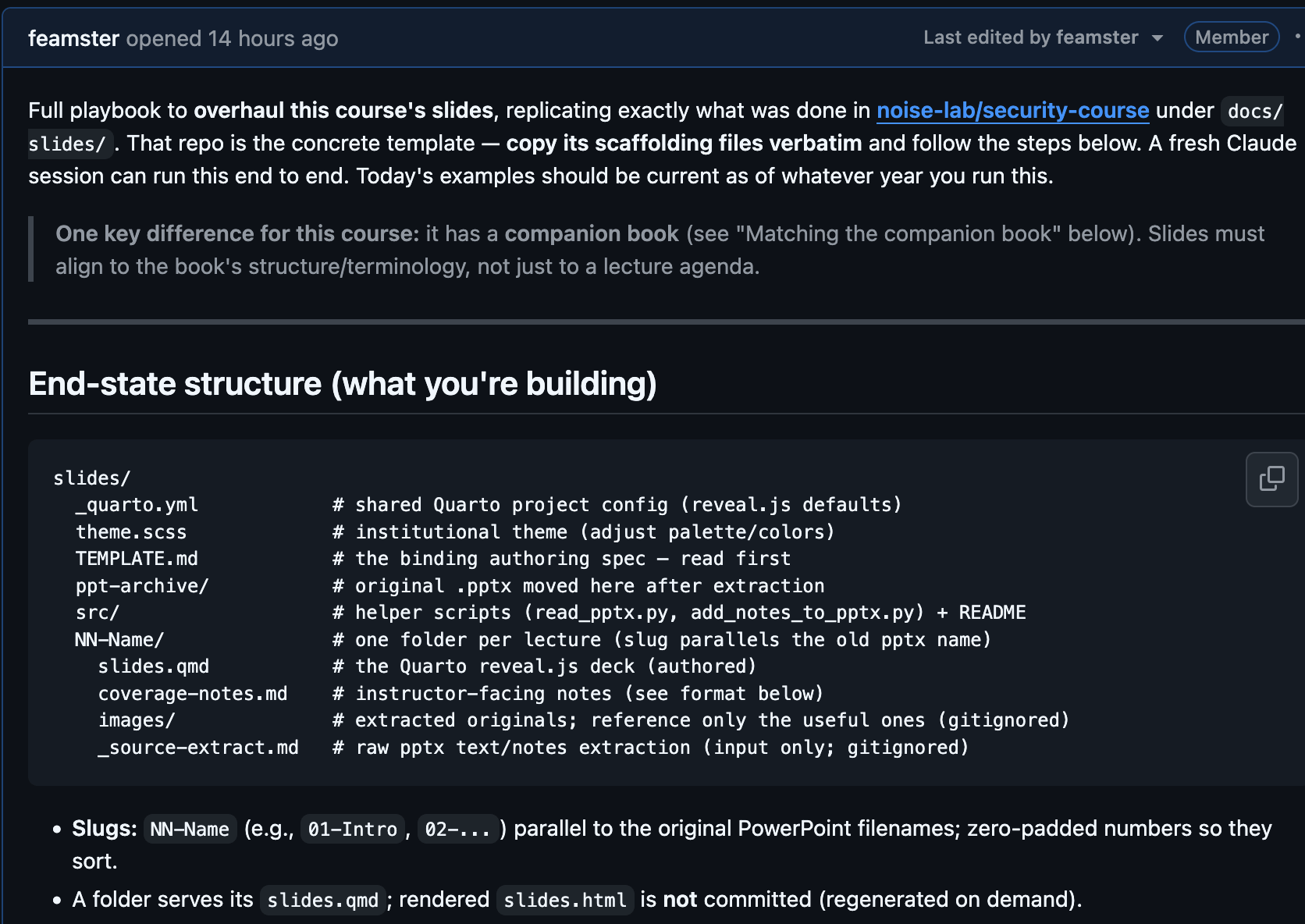
The goal wasn’t a faithful port — it was a content-driven rebuild into Quarto reveal.js: leaner decks, aligned to what I actually covered, with examples refreshed to the present.
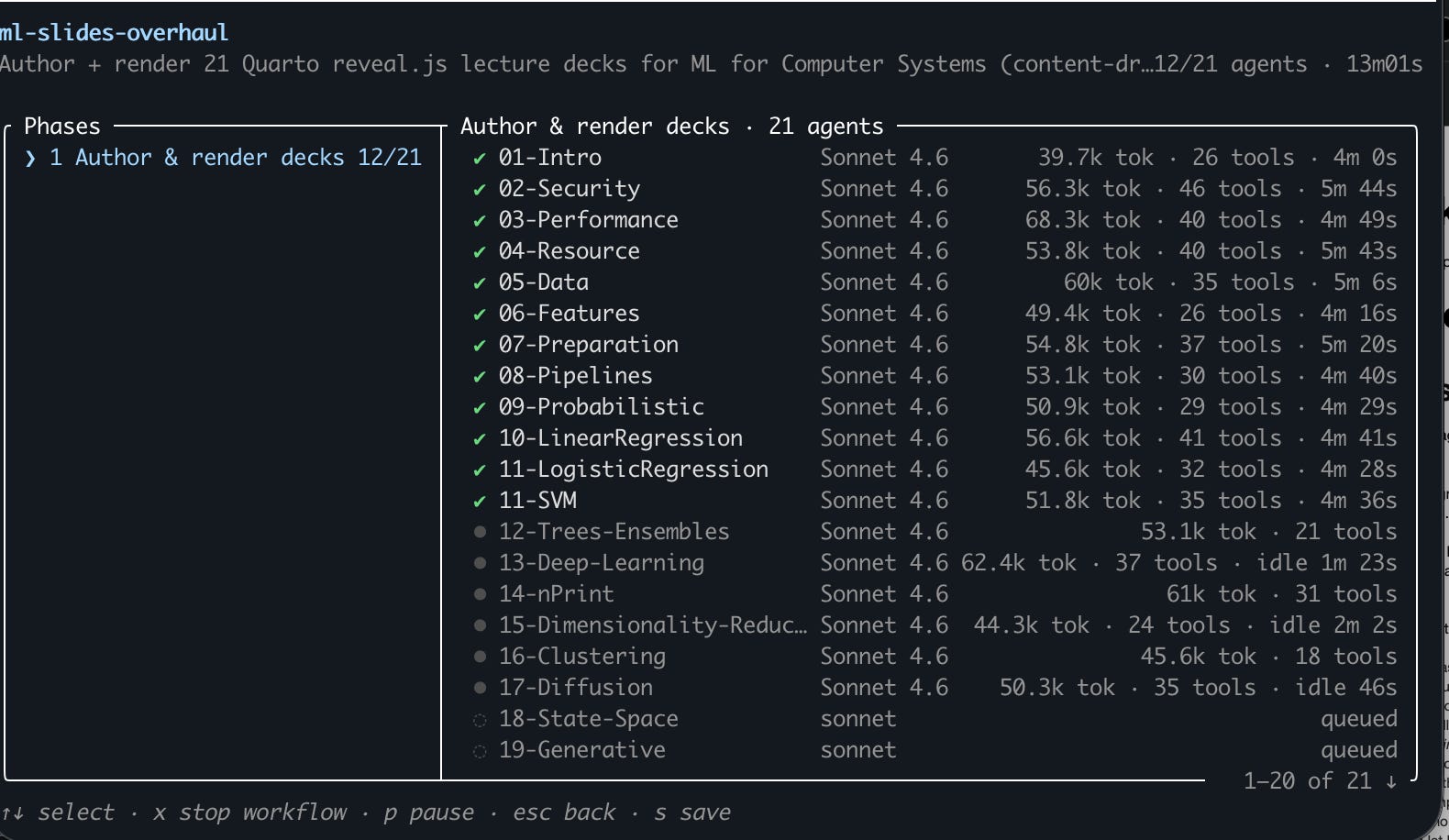
This is where multi-agent workflows earned their keep. After I hand-built one reference deck to lock the look — and approved it before anything scaled — I kicked off a workflow that fanned out one agent per deck, about six running at a time. Each agent did the following:
Read a shared template spec.
Pulled the extracted text from its deck.
Found the matching part of my agenda.
Web-searched and verified a current-events hook.
Curated the images worth keeping.
Wrote inline speaker notes.
Rendered its deck to confirm it built.
Every deck also got a coverage-notes.md: what I changed, what’s missing, and — my favorite touch — a seeded “next-year refresh” checklist of the dated facts that will go stale, so the annual update is a one-paste job next fall.
The detail I didn’t expect: the fan-out generated its own follow-up work rather than just closing the original. When I ran this same overhaul on the censorship course, the slide agents collectively noticed gaps between the decks and the companion book and filed them as a fresh missing-coverage backlog — a new issue, spun out of the overhaul, ready for the next pass. Agents producing the next spec, not just consuming the current one.
Four Shapes Of Agent Work
What struck me is that “use agents” isn’t one thing. Across this project I leaned on at least four distinct shapes:
Summarize-Then-File — read the feedback, produce the tracking issue.
Surgical Consistency Pass — make one exact string identical across eight files, no creativity wanted.
Parallel Fan-Out — one agent per slide deck (or per assignment), dozens at once, each an independent unit of work.
Playbook Issue — write an issue so complete that another agent, in another repo, can execute it cold.
That last one is the multiplier.
Issues As Portable Specs: Doing It Three Times
Once the security course was done, I didn’t want to re-explain any of it to modernize my ML systems and censorship courses. The first step in each repo was the same feedback-to-issue pattern applied again — the evals summarized and filed as a checklist (ML systems, censorship) — so each course had its own tracked backbone before any agent touched a file.
But the real reuse was the playbook issues: I had Claude write the security-course approach up as specs complete enough that a fresh Claude Code session could execute them cold. For ML systems that meant an assignments-and-materials playbook (”apply the security-course patterns”) and a slide-overhaul playbook (”migrate to Quarto, match the book”); the censorship course got its own slide-overhaul playbook.
Each one captured the exact folder structure, the extraction pipeline, the template, the workflow, the repo hygiene, and the annual-refresh loop, adapted to that course — notably, both slide playbooks align the decks to a companion book, not just a lecture agenda. For instance, the ML-systems slide issue spells out the per-deck book-chapter mapping so an agent knows which chapter each deck should track without me in the loop. Then I opened a fresh Claude Code session in each repo, pointed it at its issue, and let it run, pausing at the same reference-deck checkpoint I used the first time.
The issue stopped being a to-do list and became a transferable specification. The knowledge isn’t trapped in one conversation; it’s a document a human or an agent can pick up.
What Kept It Safe
This was fast, not reckless. I reviewed diffs before anything was committed, the agents stopped for my approval at the reference deck before fanning out, and I never let them commit or push without a confirmation. Web-sourced claims got verified, not trusted. And the work cut both ways: an agent caught the broken exam source; the permission system caught me when I tried to delete original files it judged I shouldn’t. Human-in-the-loop wasn’t a slogan — it was the reason I’d do it again.
The Takeaway
The pattern that worked is almost embarrassingly simple: make the intention explicit and tracked, then let agents execute against it. A GitHub issue turns out to be a near-perfect interface for this — it’s the spec, the checklist, the changelog, and (when written well) a portable playbook another agent can run somewhere else.
Course maintenance is the kind of important-but-deferred work that never quite justifies a free afternoon. It turns out an afternoon was enough — as long as I spent it writing the issues, and let the agents spend it doing the work.
Built With Claude Code And Its Multi-Agent Workflows.