
SwiftQueue: A Small Transformer Model for Per-Packet Latency Prediction
We reduced tail latency for real-time applications with a 100K-parameter Transformer.

L4S is finally getting deployed. After years of talking about reducing latency at the router level, ISPs are actually rolling this out—Verizon, Nokia, and others are on board. The basic idea is simple: mark your packets with an ECN bit, and L4S-enabled routers put them in the appropriate queue. Low-latency traffic gets the fast lane.
I was fortunate to be able to present this morning at the Understanding Latency 4.0 Conference on our new technology, SwiftQueue.
SwiftQueue uses a compact transformer model to perform sub-millisecond prediction of traffic latency, allowing per-packet queue assignment and reduction of tail latency by as much as 45%.

But there’s a problem with how L4S works today. It treats every packet in a flow the same way. All your video call packets get the same queue assignment, even though congestion is bursty. Some packets sail through; others hit a traffic jam and spike your tail latency. It’s that variance that kills real-time apps—not the average, the outliers.
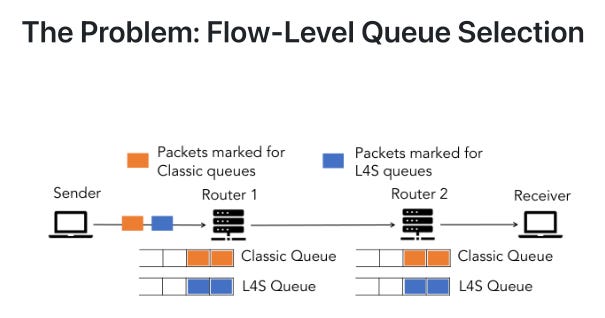
We asked a simple question: what if we could predict which packets are about to get hammered, and route them differently?
The Approach
SwiftQueue uses a Transformer—the same architecture behind large language models like ChatGPT—to predict per-packet latency based on the timing of recent ACKs. The insight is that packet-level latency variations aren’t random. They follow patterns from complex interactions at shared router queues: video apps have periodic bursts, TCP congestion control creates predictable queue buildups and back-offs. Traditional time-series models can’t capture these patterns efficiently. Transformers can.
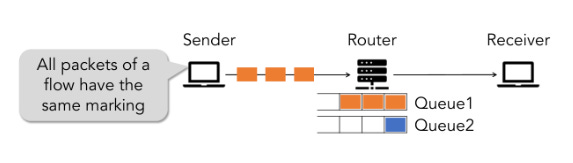
Armed with that prediction, the sender dynamically marks each packet’s header to route it to whichever queue has lower predicted latency—even if that means packets within the same flow end up in different queues.
Why Transformers?
The core innovation in Transformers is self-attention: the model learns to weigh which elements in a sequence matter for predicting what comes next. In language, “bank” means different things depending on whether “river” or “financial” appeared earlier. The same logic applies to packet latencies—a spike three packets ago might be highly predictive, or irrelevant, depending on context.
RNNs and LSTMs can learn sequences, but they suffer from vanishing gradients and memory limitations. Transformers parallelize attention across the whole context window, making them faster to train and better at long-range dependencies.
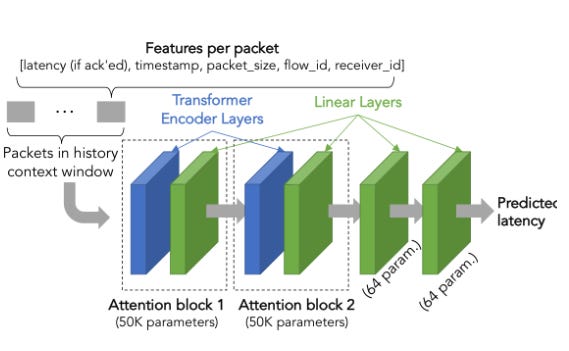
SwiftQueue’s Transformer is deliberately small—about 100K parameters, nothing like the billions in language models. Two encoder attention blocks, two linear layers. Input features include latency, timestamp, packet size, flow ID, and receiver ID. The history window is sized to the bandwidth-delay product of the link.
One nice result from the paper: even when two packets have nearly identical recent latency histories, the Transformer maps them to completely different positions in its internal feature space if one is about to experience a spike. The model learned to detect signals that aren’t obvious to human inspection.
Key Design Choices
Custom loss function. Standard MSE tries to minimize error everywhere. We don’t care about predicting smooth periods—we care about catching spikes. SwiftQueue uses a 10× penalty when true latency change exceeds 20ms and 20% relative difference. Trades slightly higher average error for dramatically better spike detection.
Fast online fine-tuning. Network conditions change constantly. SwiftQueue only fine-tunes the linear layers using the most recent minute of data—takes under 30 seconds on a commodity GPU.
Batched predictions. At 200 Mbps, you can’t wait for each ACK before predicting the next packet’s latency. SwiftQueue predicts batches of up to 8 future packets simultaneously, keeping inference under 400 microseconds.
Oscillation prevention. A naive controller could thrash between queues. SwiftQueue includes un-ACKed packets (with queue assignments but not latencies) in the prediction input, so it knows how many packets it’s already assigned to each queue.
Results
Evaluated on real traces (Netflix and Facebook traffic over WiFi and Ethernet) and NS-3 simulations:
Prediction accuracy: 45-65% higher F1 scores on sharp latency changes vs. LSTM and XGBoost baselines
Tail latency reduction: P99 latency drops 36-45% compared to default L4S or LSTM-driven selection
Show Image
SwiftQueue achieves better prediction on sharp changes by 45-65% and reduces P99 tail latency by 36-45% compared to baseline approaches.
Results hold across different network conditions—even with 500 concurrent flows or 200ms propagation delay.
Deployment Reality
SwiftQueue has some deployment considerations:
Hardware. Needs a GPU for fast inference, albeit a cheap one (TITAN RTX, 2GB peak memory utilization). Datacenter-scale with 10+ Gbps links would need beefier hardware.
Delayed ACKs. High propagation delay means less recent information to predict from. The model degrades gracefully but can’t overcome fundamental information constraints.
Scaling. Handles hundreds of concurrent flows well; thousands would need architectural changes.
Congestion control coupling. SwiftQueue only does queue selection—doesn’t touch congestion control. The predictor is trained on specific CC algorithms (primarily DCTCP+L4S) and may not generalize perfectly. TCP BBR’s probing behavior creates more random-looking patterns.
L4S availability. Assumes L4S-enabled routers along the path. Deployment is growing but not ubiquitous.
Why This Matters
This is part of a broader trend: using ML to make fine-grained, per-packet decisions that were previously impossible. Traditional congestion control operates at the flow level because that’s what humans could reason about. Neural networks don’t have that limitation.
You also don’t need billions of parameters. A 100K-parameter model, purpose-built for the domain, beats larger general-purpose architectures. Match the architecture to the problem structure.
Read More
SwiftQueue will appear at the New Ideas in Networked Systems (NINeS) Conference in 2026.
SwiftQueue: Siddhant Ray, Xi Jiang, Jack Luo, Nick Feamster, Junchen Jiang. University of Chicago. arXiv:2410.06112